📎 It looks like you're writing user stories from API docs…
How I used AI to transform complex API documentation into actionable development tickets in minutes.
How I Turned 6062 Lines of API Documentation into Actionable Development Plans
I've been working on an open source MBTA schedule app for iOS and watchOS. Looking at their API documentation (every bus, train, and station detail in Boston's transit system), I wondered if an AI agent might be good at processing all this structured information.
Turning API docs into development work usually means:
- Reading technical documentation
- Extracting important parts
- Writing user stories
- Planning implementation
- Creating tickets

In 5 minutes (and for about the cost of a coffee shop cookie - $1.20), it produced a detailed docment containing stories like the following:
**User Story**: "As a transit rider, I want to see accurate real-time arrival predictions for all routes at my stop so I can plan my boarding and minimize wait times."
**Primary Screens/Components**:
- Stop detail screen with live arrivals list
- Arrival countdown timers with status indicators
- Route-specific arrival groupings
- Pull-to-refresh for manual updates
**Core Interactions**:
- Tap stop to view all live arrivals
- Pull down to refresh predictions
- Tap arrival to view trip details
- Swipe for route-specific filtering
**Detailed MBTA API Plan**:
- **Endpoints**:
- `GET /predictions?filter[stop]={stop_id}&sort=time&include=route,trip,vehicle,schedule,alerts`
- `GET /schedules?filter[stop]={stop_id}&sort=time&include=route,trip` (fallback)
- `GET /stops/{id}?include=parent_station,child_stops,facilities`
- **Example URLs**:
- `https://api-v3.mbta.com/predictions?filter[stop]=place-dwnxg&sort=time&include=route,trip,vehicle,schedule,alerts&api_key={key}`
- `https://api-v3.mbta.com/stops/place-dwnxg?include=parent_station,child_stops,facilities&api_key={key}`
- **Polling Strategy**: 15-second intervals when app is active, 30-second when backgrounded
- **Caching**: Live predictions cached for 15 seconds, stop metadata for 6 hours
- **Error Handling**: Fall back to scheduled times when predictions unavailable, show uncertainty indicators
**Performance and Accessibility**:
- VoiceOver announcements for arrival updates
- Haptic feedback for imminent arrivals (< 2 minutes)
- Dynamic text sizing for arrival times
- Color-coded status indicators with text alternatives
**Test Cases**:
- Real-time prediction accuracy
- Fallback to scheduled times
- Multi-route stop handling
- Accessibility compliance
- Network error recovery
**Telemetry Considerations**:
- Track prediction accuracy vs actual arrivals
- Monitor API response times
- Measure user engagement with arrival details
💡 Why this actually works
Three key points:
- One-time task - Perfect for that initial heavy lifting of understanding and organizing
- Structured input - API docs (especially Swagger/OpenAPI) are already machine-readable
- Verifiable output - Everything it suggests can be tested
🔍 The verification trick that makes this bulletproof
While Postman lets you directly import Swagger/OpenAPI specs, try asking the AI to generate a Postman collection based on the user stories it created:
Standard Swagger Import:
- Raw endpoint-by-endpoint organization
- No context around usage patterns
- Need to create/manage environment to set the API key
- Technical but not practical grouping
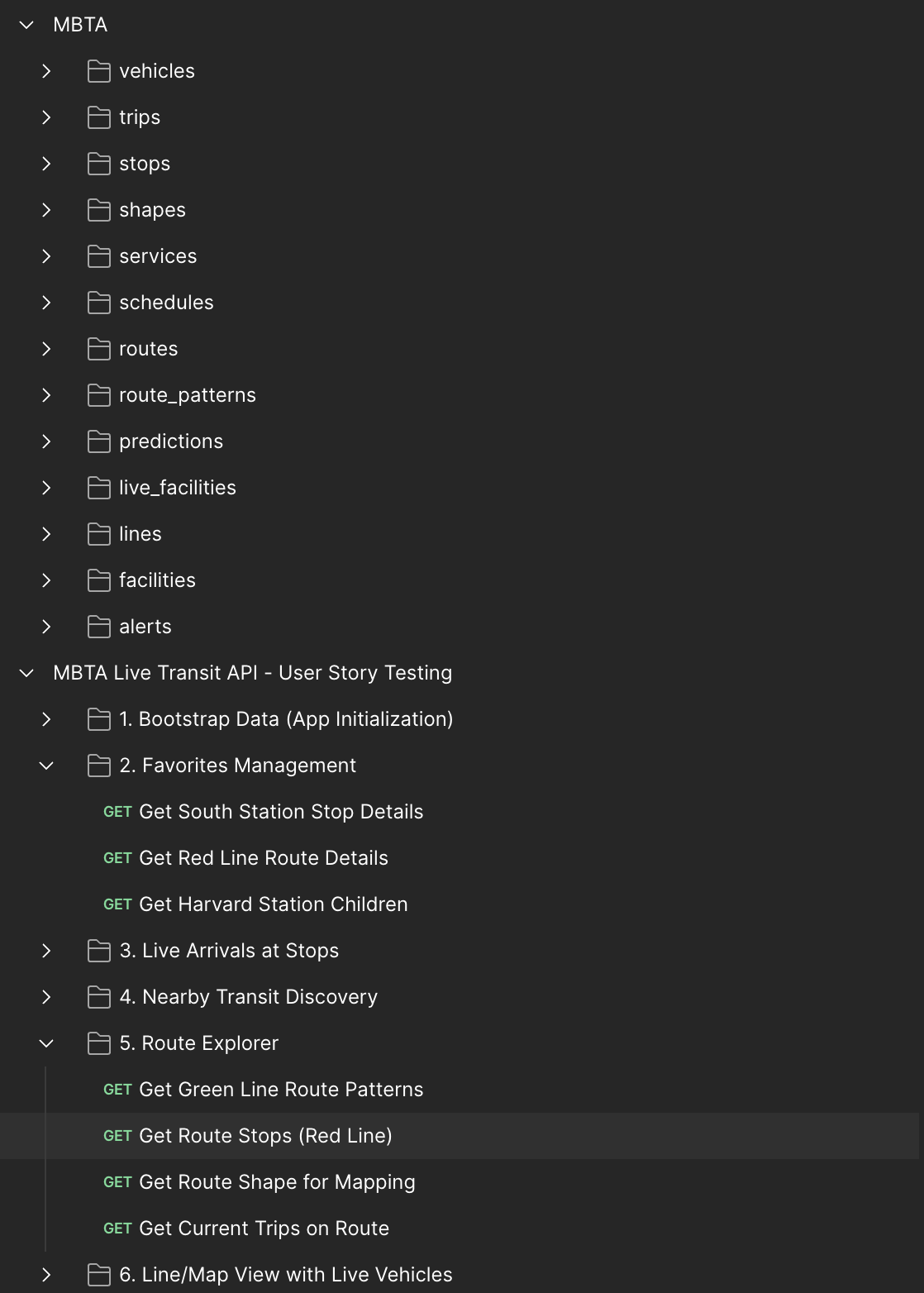
AI-Generated Collection:
- Grouped by user stories and functionality
- Single API key configuration for the whole collection
- Practical testing flows that match your use cases
- Ready to verify the exact features you'll build
"item": [
{
"name": "Get All Routes",
"request": {
"method": "GET",
"header": [
{
"key": "Accept",
"value": "application/vnd.api+json",
"type": "text"
}
],
"url": {
"raw": "{{base_url}}/routes?fields[route]=id,short_name,long_name,color,text_color,type,sort_order,description,direction_names,direction_destinations&sort=sort_order",
"host": ["{{base_url}}"],
"path": ["routes"],
"query": [
{
"key": "fields[route]",
"value": "id,short_name,long_name,color,text_color,type,sort_order,description,direction_names,direction_destinations"
},
{
"key": "sort",
"value": "sort_order"
}
]
},
"description": "Fetch all routes for route picker, favorites, and search functionality. Used in M0-M1 milestones."
},
"response": []
}
]
When this approach shines (and when it doesn't)
This works best for:
- Well-documented APIs with clear Swagger/OpenAPI specs
- Stable-ish systems where changes are infrequent but significant
- New integrations where you need to understand the whole landscape quickly
But it's less helpful when:
- APIs change daily - the overhead of keeping context fresh becomes too much
- Documentation is poor - garbage in, garbage out
- You already know the API well - human expertise beats AI for familiar territory
The bigger picture: APIs that evolve
Most real APIs aren't static, which raises an interesting question: how do you keep your AI assistant up-to-date as things change?
The emerging answer seems to be smart, selective updates. Instead of re-processing everything when something changes, you can:
- Set up systems that watch for schema changes and update just those parts
- Use tools that automatically refresh documentation when code changes
- Focus AI queries on recently changed sections rather than the whole API
Think of it like having a research assistant who only reads the new chapters of a book, rather than starting from page one every time.
The real value of this approach comes from:
- Clear starting context - Begin with a better picture of what you're building
- Ready-to-use outputs - Perfect for sprint planning, team discussions, and implementation guides